Pytorch中的Convolution layers
学习Pytorch中的卷积相关。
互相关和卷积的区别
在CNN中,互相关和卷积都是使用filter/kernel对一张图像进行操作
互相关是从上到下,从左到右
卷积是从下到上,从右到左
卷积等同于将卷积核沿着x轴y轴翻转后,再进行互相关操作
在CNN中,为了简化操作,通常直接使用互相关来代替卷积,因为对于网络来说,无论是否翻转,都只不过是网络要学习的参数,翻转与否其实并无影响,所以互相关和卷积在这种情况下是等同的
Pytorch 中的ConvNd
[官方文档](torch.nn.modules.conv — PyTorch 1.9.0 documentation)
[中文文档](torch.nn · Pytorch 中文文档)
Pytorch中的卷积层操作有三种,分别对应了一维,二维和三维,对于函数的参数以及相关说明,文档中都有详细的介绍,这里略过不提,本文更多的是对自己的理解以及感悟的记录,将会以问题的形式表达
1. 卷积是如何实现维度变化的
无论卷积操作的维度是多少,通过卷积核之后,输入的特征都可以发生维度的变化,比如输入的是点云数据的张量,维度是[B, 3, N],对应的一维卷积的卷积核是[Cout, 3, Size],其中Cout就代表了输出的维度,Size就是卷积核的大小,因为是一维卷积核,所以大小维度是1[注意是维度,不代表大小直接为1]
关于卷积核尺寸的定义,我将相关参数分为两种,一种参数定义卷积核的数量,这些参数包括了卷积操作的输入维度,以及卷积操作的输出维度;另一种参数定义卷积核的大小,比如在一维卷积中,kernel size就是一个一维的数值,如果需要关注上下文信息,就将其大小设置为大于1,或者像PointNet网络中设定的那样,将一维卷积核的大小设置为1,只学习一个点的特征信息
那么最终,一个卷积核的shape应该是 [Cout, Cin, kernelSize],具体来说,Cin*kernelSize大小的卷积核与输入的Cin维度的特征进行卷积,然后为了输出Cout维度的特征,需要重复Cout份,所以总的大小就是Cout*Cin*kernelSize
注:既然明确了卷积核的参数以及卷积核的shape,那么还有一点要知道,这些卷积参数都是需要经过网络学习的,那么对应的卷积操作的参数量计算,结果等同于上述计算的卷积核大小
2. 卷积核的大小如何影响卷积效果的
首先说明,这个卷积核的大小指的是上述卷积核shape中的kernelSize
关于这个问题,是我在学习PointNet时想到的,因为点云数据索引的无序性,所以PointNet学习点云特征时,不能让网络学习到点与相邻点的局部信息,只能单独地学习每个点的特征,那么从感官上来看这样做是有问题的。后面的PointNet++用了那么多繁复的操作,其实最终目的也是为了让网络学习更多的局部感知信息而已
所以经过思考后,关于卷积核的尺寸大小如何影响卷积效果的,其最直观的答案就是,kernelSize设置不同大小尺寸时,会直接影响网络对于输入特征的感知能力,而这在深度学习领域有一个专有名词,叫做感受野(Receptive Field)
虽说卷积核的尺寸越大,越能感知更多的局部信息,但是对应的也会带来两个问题
- 背景噪声的加入
- 参数量的增加
所以实际设计网络结构时,还是尽可能地考虑周全
3. 1*1卷积核的作用[Bottleneck]
Bottleneck机制的产生,就是为了让CNN能够在少量参数的前提下,学习到深层次的特征
具体方案就是使用 1×1的卷积升维,卷积核是小-> 大 -> 小的结构
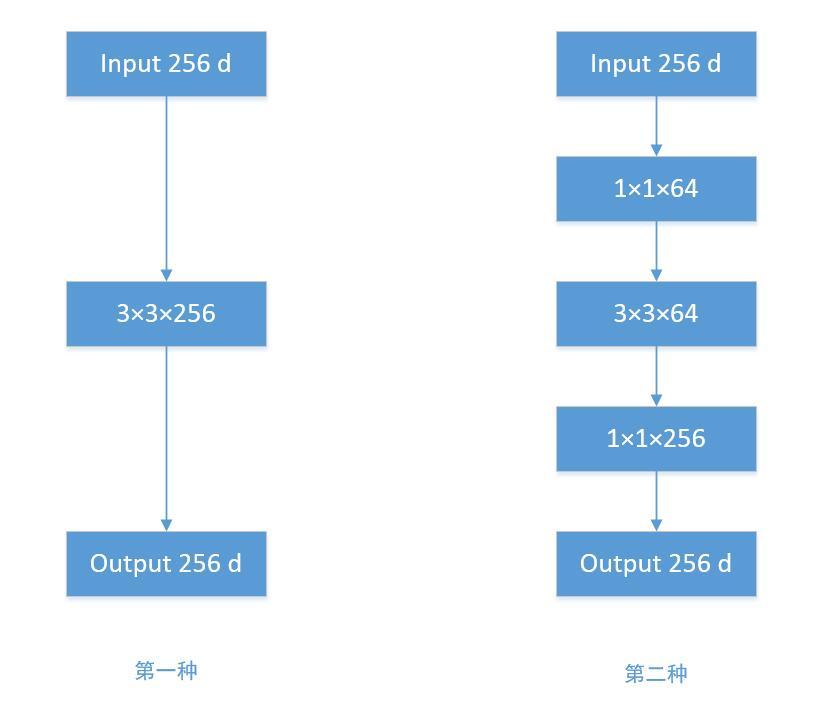
第一种的参数量为:256×3×3×256 = 589824
第二种的参数量为:256×1×1×64 + 64×3×3×64 + 64×1×1×256 = 69632
可见这种Bottleneck机制能有效降低CNN的参数量
参考:https://davex.pw/2018/02/01/guide-for-kernel/
4. 空洞卷积核的机制
空洞卷积的原理就是通过对卷积核进行改变,将卷积核增加了扩张率(dilation rate)的概念,如下图,对卷积核每个卷积核之间加入了扩张距离,这样做的好处就是让网络在不增加参数量的情况下,提高感受野,下图的感受野从3*3变为了5×5

不过空洞卷积也有缺点:
- 不适用于精度较高的任务,比如像素级别的任务,因为计算卷积时,不是感受野中所有的像素都用来计算了,这样会损失信息,这也叫
Gridding Effect网格效应 - 想不起来了,,等想起来再补充。。。
5. 可变形卷积核的原理
接下来这个卷积核的设计思路是我认为比较合理的,因为卷积核的作用是改变维度,进而提高感受野,那么对于不同的任务来说,可能一味提高感受野并不是好事,因为感受野如果不能较好地覆盖前景目标,反而引入了太多的背景信息,那么就会让网络学习到错误的特征,所以如何让感受野可变形?似乎是一个很好的研究方向
微软亚洲研究院(MSRA)就做了相关的研究,让卷积核自己形变,通过参数学习来决定感受野的覆盖区域,这是更加智能的方式
 图片目标跟踪算法Ocean中,也使用了这种可变形卷积核,来让网络更好地关注前景目标,也得到了不错的结果,感兴趣的小伙伴可以了解下
图片目标跟踪算法Ocean中,也使用了这种可变形卷积核,来让网络更好地关注前景目标,也得到了不错的结果,感兴趣的小伙伴可以了解下